Qizhen Weng 翁祈桢
AI Infra Team Lead. Research Scientist. Ph.D. in CSE from HKUST.

My research interests encompass AI Infrastructure, Machine Learning Systems, and Cloud Computing, with a particular emphasis on enhancing GPU cluster efficiency and optimizing training performance for large-scale generative models, such as large language models (LLMs), multimodal LLMs (MLLMs), and diffusion transformers (DiTs).
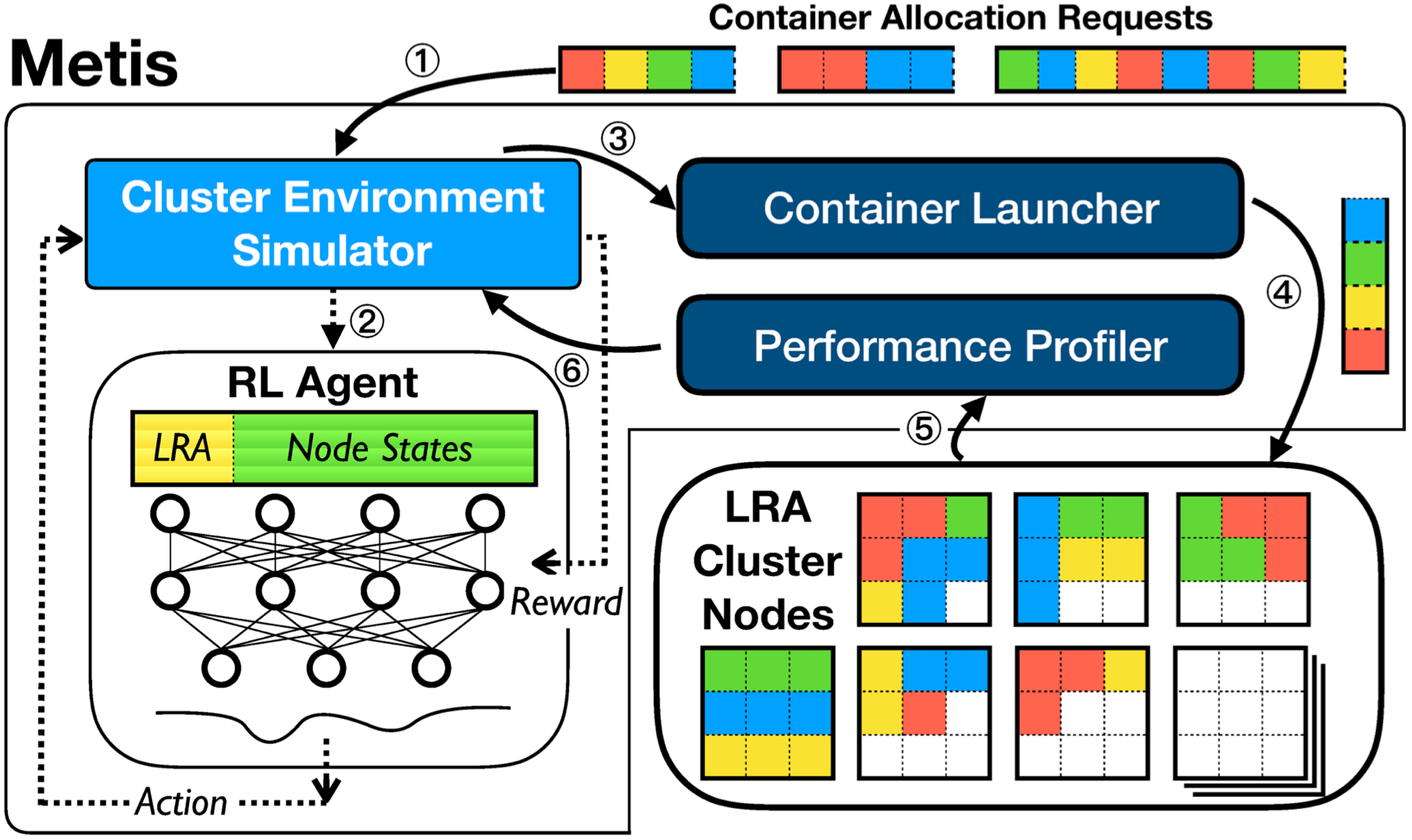
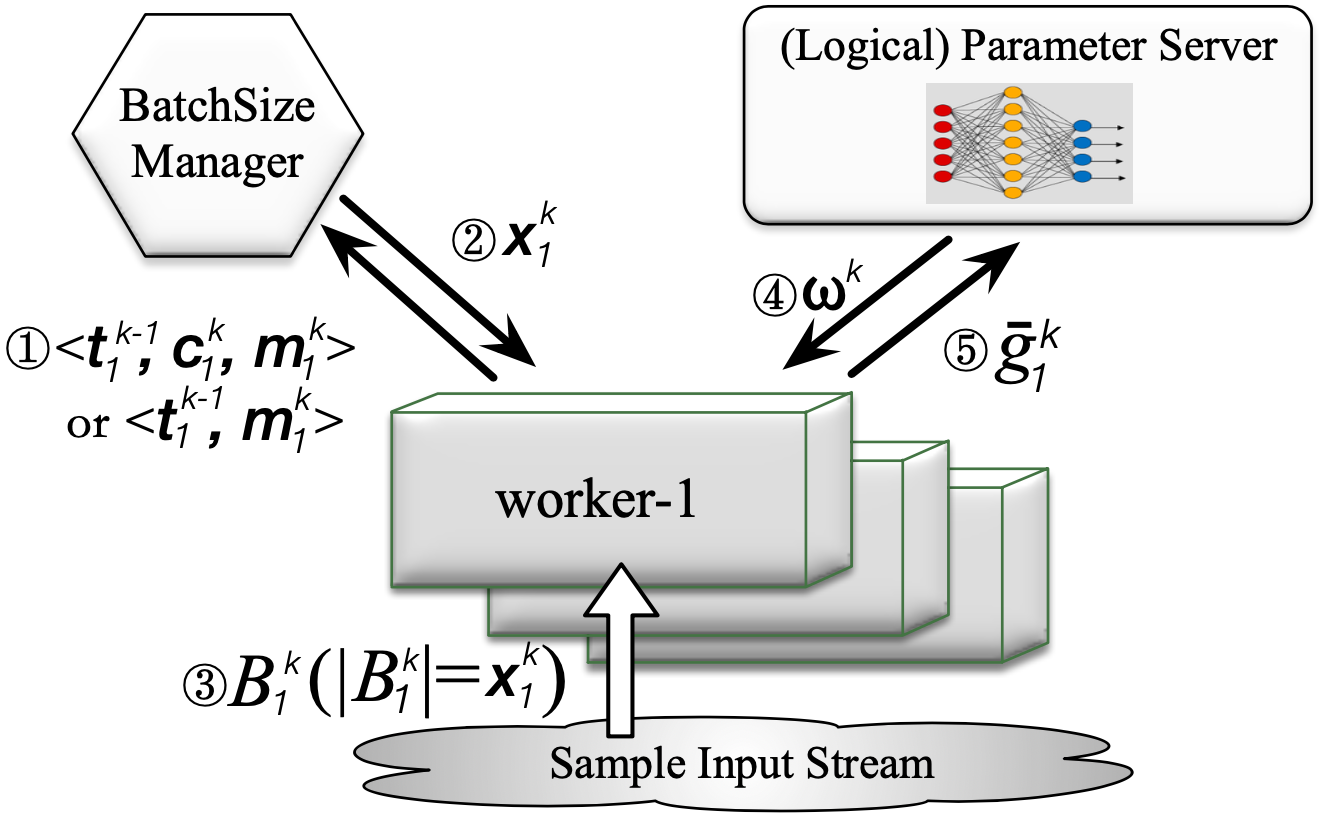
(1) Since 2024, I have been leading the AI Infrastructure Research Center at the Institute of Artificial Intelligence (TeleAI), China Telecom, where I oversee initiatives to advance AI system capabilities. (2) Prior to this, I joined the Shanghai AI Laboratory in 2022 as a Systems Researcher, contributing to the systems for large language model training and inference. (3) Earlier, I gained valuable experience as a Research Intern at Alibaba Cloud & Alibaba Group, where I focused on GPU cluster management and AI job scheduling for over two years, beginning in 2020.
I received my Ph.D. in Computer Science and Engineering from The Hong Kong University of Science and Technology in 2022, under the guidance of Prof. Wei Wang. I also hold a B.Eng. degree from Shanghai Jiao Tong University in 2017 and enriched my academic journey with a study period at UC Berkeley in 2015.
Awards
- Young Elite Scientists Sponsorship Program, CAST, 2025: for AI development tools and infrastructure
- Hong Kong PhD Fellowship Scheme, RGC of HK, 2017: awarded to 231 top students worldwide
- Shanghai Outstanding Graduates, SH Gov., 2017: awarded to top 3% students in the college
- Cyber-Security Scholarship, CIDF, 2016: awarded to 1% students in the major
News & Highlights
| Jan 31, 2026 | 📜EuroSys 2026: Suika, a cluster training system that supports efficient and high-quality rescheduling for 3D-parallelized LLM training jobs, is accepted to EuroSys 2026! See our paper “Suika: Efficient and High-quality Rescheduling of 3D-parallelized LLM Training Jobs in Shared Clusters” for details. |
|---|---|
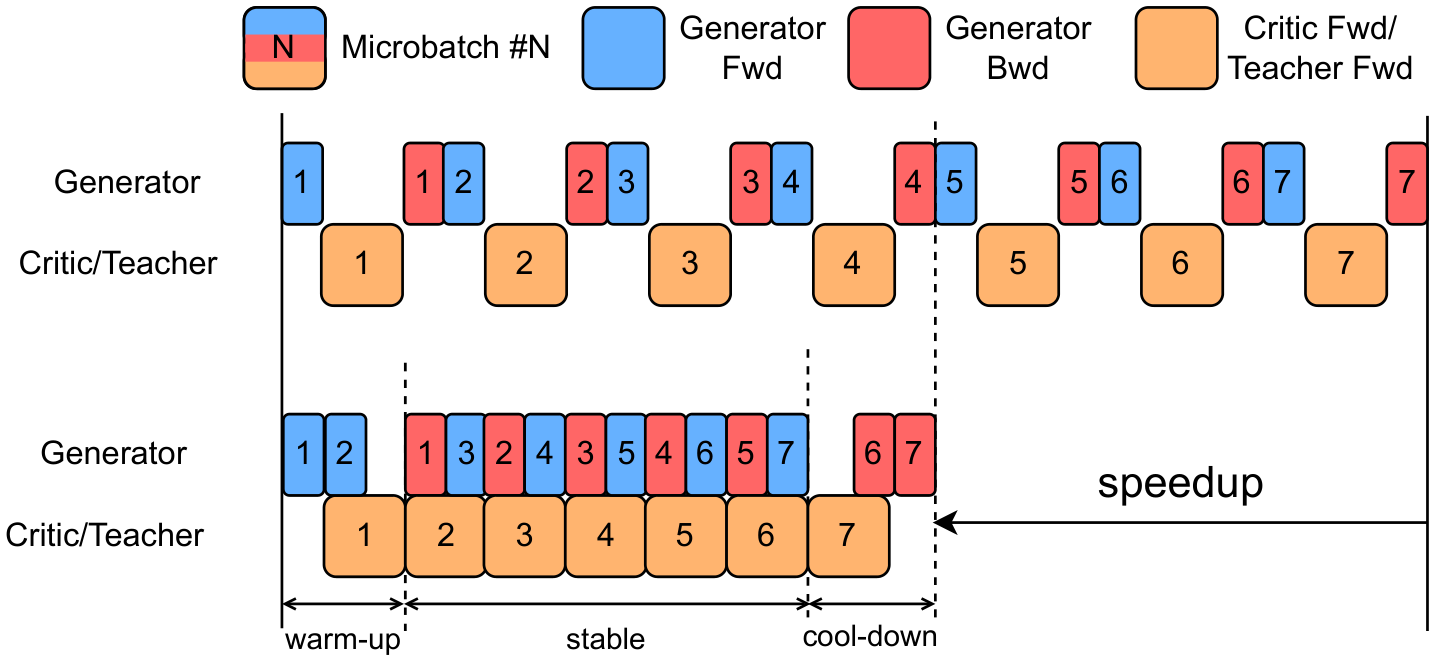
| Nov 21, 2025 | ♻️AI for Good Global Submmit: I presented “China Telecom drives ubiquitous intelligence through AI Flow”. Positioned at the intersection of AI and communications infrastructure, AI Flow aims to enable ubiquitous intelligence by bridging the gap between devices, edge computing, and the cloud. |
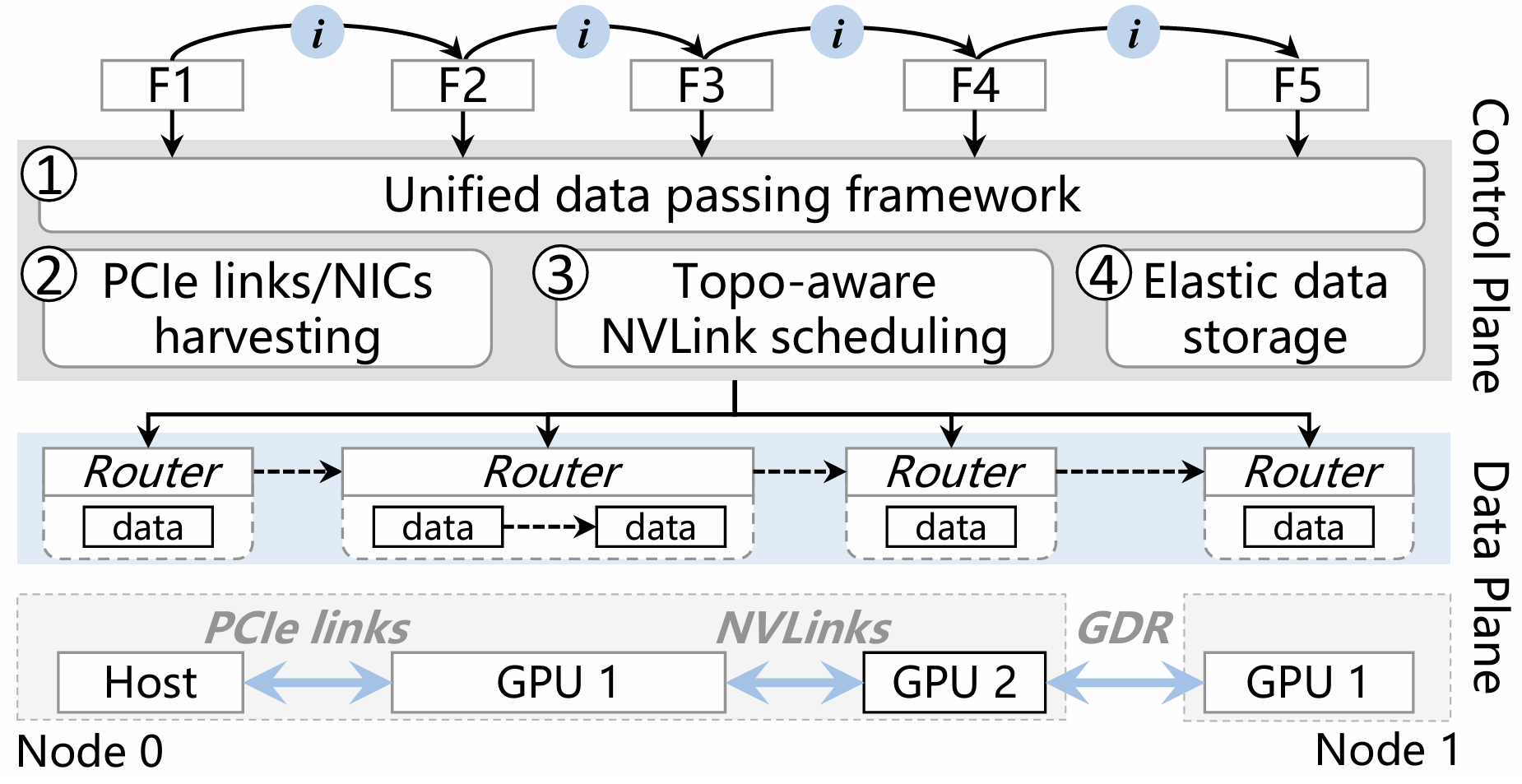
| Aug 23, 2025 | 📜EuroSys 2026: GRouter, a GPU-centric data plane system designed for serverless inference workflows, is accepted to EuroSys 2026! See our paper “Efficient Data Passing for Serverless Inference Workflows: A GPU-Centric Approach” for details. |
| Jun 15, 2025 | ♻️Invited Keynote Speaker at AI for Good Global Submmit: I will be delivering a Keynote speech on AI Solutions in China Telecom at the AI for Good Global Summit 8-11 July in Geneva, hosted by the ITU of the United Nations. Join us as we discuss how AI can shape a sustainable future! |
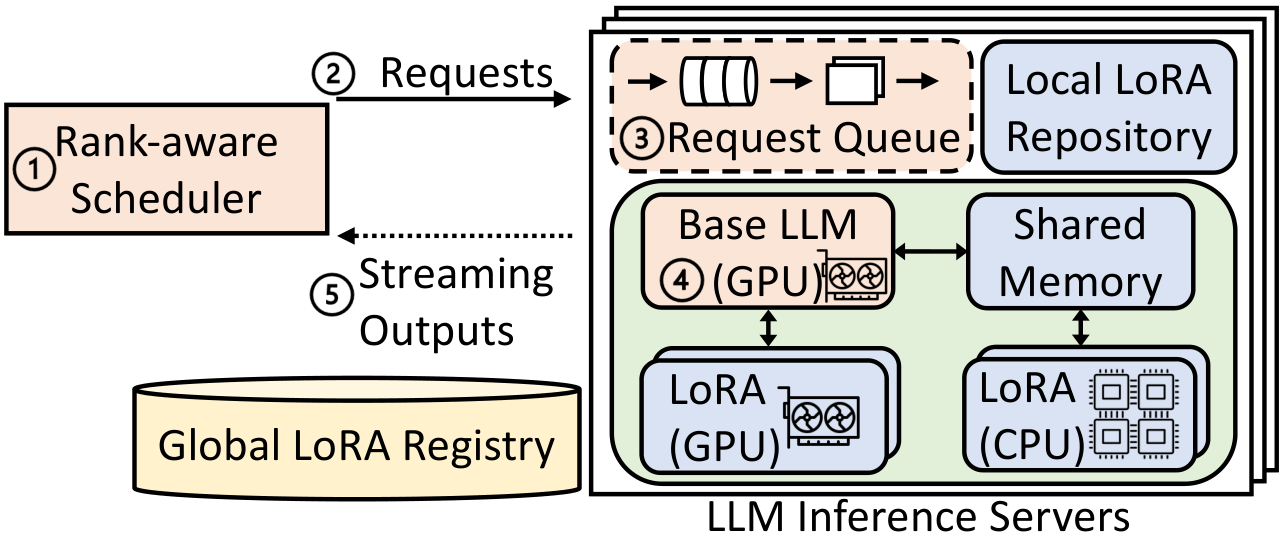
| Apr 1, 2025 | 📜USENIX ATC 2025: Toppings, an efficient multi-tenant system that serves many LoRA adapters with a common base LLM, is accepted to USENIX ATC 2025! See our paper “Toppings: CPU-Assisted, Rank-Aware Adapter Serving for LLM Inference” for details. |